








ECM 的模型相当漂亮,但是问题的定义很不合理,不合理在哪呢?这个模型是在给出 context,同时给出你想要生成的 response 的 emotion,然后生成一句带有这个 emotion 的 response。但是在日常对话中,并不会有上帝去给你指定要回复的 emotion。

这个解码是基于 diverse beam search 的,diverse beam search 是在 beam search 的基础上,把 top B 序列分成 G 个 group,然后加一个额外的惩罚项,这个惩罚项的目的在于让 group A 中下一时刻的 search 出来的东西尽可能和其他 group 下一时刻 search 出来的东西不一样,这就达到了 diverse 的目的。这里也从两个 level 来衡量,一个是单个词的情绪,一个是整个句的情绪,标准就用向量的 cosine 函数来衡量相似度。

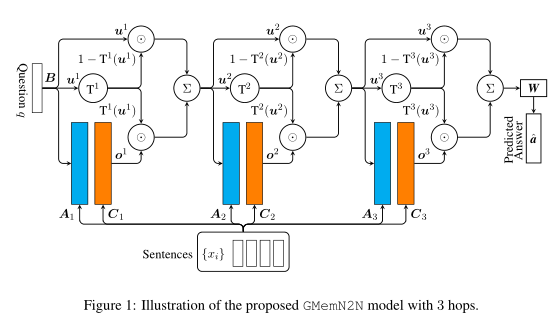
也就是修改一下原来模型中输出层的公式即可。然后参数 W 和 b 有全局和每个 hop 独立两种方式,后面实验结果证明,每个 hop 保持独立效果会比较好。论文的创新点倒不是很大,只不过是将两篇论文结合一下,但是看有实验效果好像还有挺大的提升。最终的模型架构图如下所示:
实际上个人看来这个也是开放域对话之后一个很好的研究方向,毕竟有太多的 paper 去解决如何不产生“呵呵”这种无意义回答的问题了,只有真正的模拟人类的交谈才是好的 chatbot。
在这个 loss function 处,作者做的假设是:两个人聊天,情感不会太迅速或者频繁转变。举个栗子:你说一句比较友好的话,我也会回你一句比较友好的话,就是客套呗;你说一句挑衅的话,我会回你一句比较愤怒的话。很自然的,loss function 不但要考虑交叉熵还要考虑生成 response 的情感和 input 的情感是不是接近,这里用欧氏距离来衡量。如下:
总体看来在 seq2seq 的三个必要的步骤里都做了情感的改进,不过方法看上去依然有点勉强,没有明显建模情感的交互,不过也算是对话系统里的一个情感的初步尝试。
近年来,基于神经网络的深度学习方法在自然语言处理领域已经取得了不少进展。作为 NLP 领域的基础任务—命名实体识别(Named Entity Recognition,NER)也不例外,神经网络结构在 NER 中也取得了不错的效果。其中,正如这篇论文,同一时期出现了很多类似的 NN-CRF 结构来进行 NER,并成为目前主流 NER 模型,取得了不错的效果。在此进行一下总结,和大家一起分享学习。
在基于机器学习的方法中,NER 被当作是序列标注问题。与分类问题相比,序列标注问题中当前的预测标签不仅与当前的输入特征相关,还与之前的预测标签相关,即预测标签序列之间是有强相互依赖关系的。例如,使用 BIO 进行 NER 时,正确的标签序列中标签 O 后面是不会接标签I的。
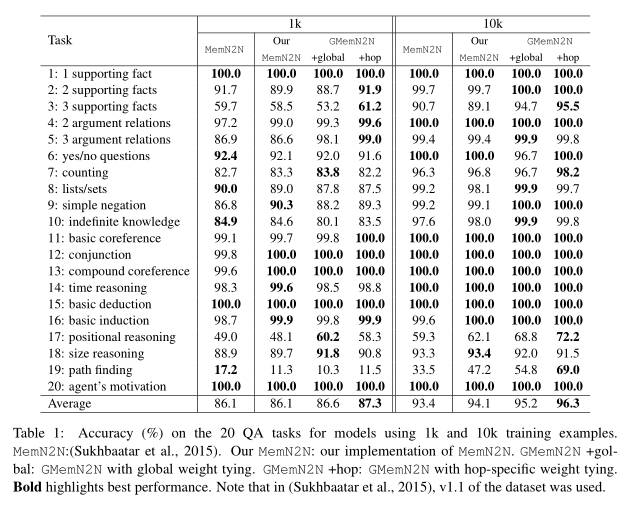
本文所提出的模型不仅仅在 bAbI 数据集上取得了很好的效果,而且在 dialog bAbI 对话数据集上也取得了很好的效果。这个数据集应该会在后面的文章中进行介绍,这里就不赘述了。这里也贴上两张实验结果的图:
对于深度学习方法,一般需要大量标注数据,但是在一些领域并没有海量的标注数据。所以在基于神经网络结构方法中如何使用少量标注数据进行 NER 也是最近研究的重点。其中包括了迁移学习《Transfer Learning for Sequence Tagging with Hierarchical Recurrent Networks》和半监督学习。
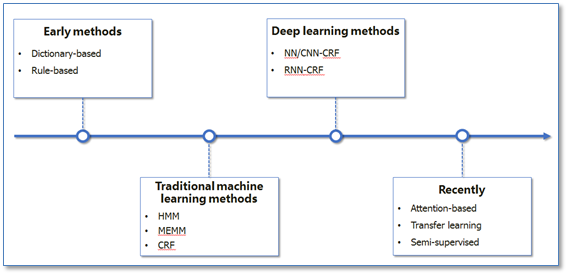
命名实体识别(Named Entity Recognition,NER)就是从一段自然语言文本中找出相关实体,并标注出其位置以及类型,如下图。它是 NLP 领域中一些复杂任务(例如关系抽取,信息检索等)的基础。NER 一直是 NLP 领域中的研究热点,从早期基于词典和规则的方法,到传统机器学习的方法,到近年来基于深度学习的方法,NER 研究进展的大概趋势大致如下图所示。
在训练阶段,作者也给出了两种目标函数:一种是词级别的对数似然,即使用 softmax 来预测标签概率,当成是传统一个分类问题;另一种是句子级别的对数似然,其实就是考虑到 CRF 模型在序列标注问题中的优势,将标签转移得分加入到了目标函数中。后来许多相关工作把这个思想称为结合了一层 CRF 层,所以我这里称为 NN/CNN-CRF 模型。
第二张图揭示得是 MemNN 与本文提出模型各个 hop 对每个句子的权重计算,可以看出本文的模型更加集中在最重要的那个句子上面,而 MemNN 则比较分散,也说明了本文模型效果更好。
然后我们来看一下如何将其融入到 End-To-End Memory Networks 中,由于其每个 hop 的功能都可以视为 u=H(u),所以对应到上面的公式,u 就相当于输入 x,o 就相当于输出 y,所以代入上式得:
作者在这里提出了三个不同的 loss function,其实在我看来也是不得已而为之,因为它没有更好的办法融合这些东西。

实验结果表明,在少量标注数据上,加入这个语言模型向量能够大幅度提高 NER 效果,即使在大量的标注训练数据上,加入这个语言模型向量仍能提供原始 RNN-CRF 模型的效果。整体模型结构如下图:
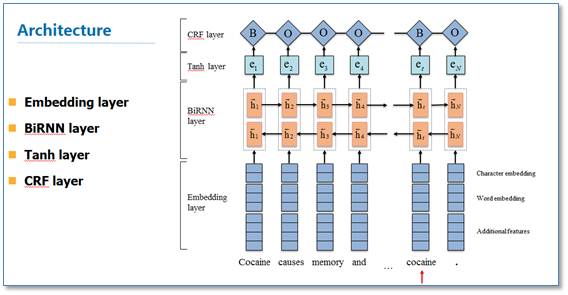
它主要有 Embedding 层(主要有词向量,字符向量(在字符向量实现的具体方法上,有使用 CNN 比如这篇论文,还有使用 RNN,不过效果我感觉差不多)以及一些额外特征),双向 RNN 层,tanh 隐层以及最后的 CRF 层构成。它与之前 NN/CNN-CRF 的主要区别就是他使用的是双向 RNN 代替了 NN/CNN。这里 RNN 常用 LSTM 或者 GRU。
基于神经网络结构的 NER 方法,继承了深度学习方法的优点,无需大量人工特征。只需词向量和字符向量就能达到主流水平,加入高质量的词典特征能够进一步提升效果。对于少量标注训练集问题,迁移学习,半监督学习应该是未来研究的重点。
论文的实验部分我就不介绍了,最后进行一下总结,目前将神经网络与 CRF 模型相结合的 NN/CNN/RNN-CRF 模型成为了目前 NER 的主流模型。我认为对于 CNN 与 RNN,并没有谁占据绝对的优势,各自有相应的优点。由于 RNN 有天然的序列结构,所以 RNN-CRF 使用更为广泛。
文章中具体的做法是将传统的词向量和这个情绪向量 W2VA 连在一起,作为 encoder 和 decoder 的 input。其实这个方法和 emotion chatting machine 的第一步是异曲同工的,只不过在 ecm 中这个情绪向量是学来的,没有用外部词典。
在这篇论文中,作者提出了窗口方法与句子方法两种网络结构来进行 NER。这两种结构的主要区别就在于窗口方法仅使用当前预测词的上下文窗口进行输入,然后使用传统的 NN 结构;而句子方法是以整个句子作为当前预测词的输入,加入了句子中相对位置特征来区分句子中的每个词,然后使用了一层卷积神经网络 CNN 结构。
实验结果表明 RNN-CRF 获得了更好的效果,已经达到或者超过了基于丰富特征的 CRF 模型,成为目前基于深度学习的 NER 方法中的最主流模型。在特征方面,该模型继承了深度学习方法的优势,无需特征工程,使用词向量以及字符向量就可以达到很好的效果,如果有高质量的词典特征,能够进一步获得提高。
而残差网络则可以视为是Highway网络的一种特例,因为其直接把 T 和 C 都当做 I,所以就相当于 y=H(x) + x。但是这里背后的原理我还没来得及搞明白,为什么这样就可以让更深的网络很容易就训练成功,等有时间再看看相关的论文学习下。
简单地说就是现在有个已经其他人评估好的词向量表了,词向量维度三维,每一维度分别采用感情的一个方面,表示形如:(V_score, A_score, D_score)。如果训练集中的单词在这个 VAD 表里,就取这个词向量;如果是不在表中的 oov 词,取 [5, 1, 5] 作为比较中性的词,其实就相当于我们平时处理 oov 词时候的 unk 一样。
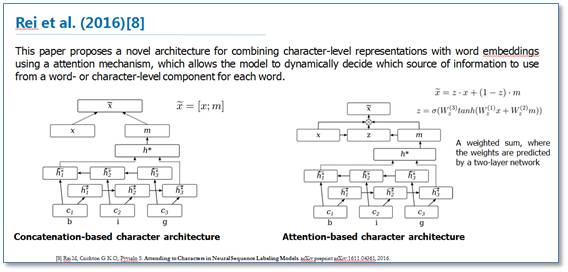
这里我提一下最近 ACL2017 刚录用的一篇论文《Semi-supervised sequence tagging with bidirectional language models》。该论文使用海量无标注语料库训练了一个双向神经网络语言模型,然后使用这个训练好的语言模型来获取当前要标注词的语言模型向量(LM embedding),然后将该向量作为特征加入到原始的双向 RNN-CRF 模型中。
都说人工智能要有情感,能体会到人的喜怒哀乐,今天就来介绍一篇带有情绪的 chatbot。在以往的研究中,大部分对话系统都只关注生成对话的语法语义是否合理,这里面有考虑上下文的,有结合主题的,有生成长句子的等等。但很少有对话系统关注情感,这是很不合理的。因为在聊天中,当一个人表示难过的时候,另一方经常会回应适当的安慰;当一方感到开心时,另一方也会为其感到快乐。就好比 A 说“我的宠物狗去世了”,B 很自然应该回复“我为你感到难过”这样类似的话,同时这种带有情感交互的例子在我们日常对话中数不胜数。

在这里,作者又做了个假设,比如两个不太熟的人聊天,一个人过分友好可能会引起另一个人的反感。然后就尽可能让两句话情感不一致,把上面公式的第二项的符号换一下就好了。loss function 符号为 LDMAX。
文章用的是康奈尔电影对话数据集,评估没有采用 BLEU,ROUGE,METEOR 等作为指标,而是采用找人来评估,能够理解这种做法,因为 BLEU 等指标对于这种对话来说实际上意义不大,而且可能效果还不如别人的好。注意,在使用情感的 loss function 方法上,先使用普通交叉熵目标函数训练 40 个 epoch,然后再使用特定的 loss function 训练 10 个 epoch。文中提到如果上来就使用特定的 loss function 训练,生成回答的语法会很差。
最近的一年在基于神经网络结构的 NER 研究上,主要集中在两个方面:一是使用流行的注意力机制来提高模型效果(Attention Mechanism),二是针对少量标注训练数据进行的一些研究。
因为 End-To-End Memory Networks 已经很熟悉了,所以我们先来介绍一下 Highway Networks 的想法。其主要是在网络输出下一层之前引入了一个 transform gate T 和一个 carry Gated C,以让网络学习什么、多少信息应该被传到下一层。我们假设本层网络的输出为:y=H(x),那么就加入下面的映射函数:
这里是想要模型生成出的句子具有很明显的情感特征,以避免生成那种无聊的话,但并不需要指定情感是积极还是消极。变向地,这也是一种避免产生”呵呵“,”我不知道“的一种方法。loss function 如下:
借鉴上面的 CRF 思路,在 2015 年左右出现了一系列使用 RNN 结构并结合 CRF 层进行 NER 的工作,其中就包括了这篇论文。代表工作主要有:
在传统机器学习中,条件随机场(Conditional Random Field,CRF)是 NER 目前的主流模型。它的目标函数不仅考虑输入的状态特征函数,而且还包含了标签转移特征函数。在训练时可以使用 SGD 学习模型参数。在已知模型时,给输入序列求预测输出序列即求使目标函数最大化的最优序列,是一个动态规划问题,可以使用维特比算法进行解码。不过 CRF 依赖于特征工程,常用的特征如下:
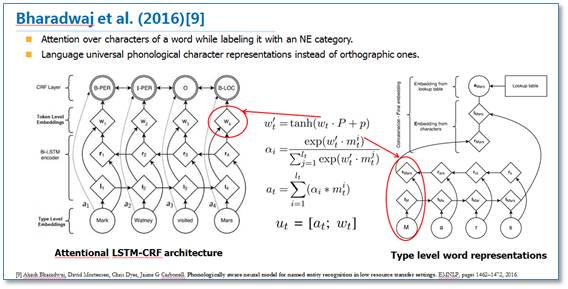
《Attending to Characters in Neural Sequence Labeling Models》该论文还是在 RNN-CRF 模型结构基础上,重点改进了词向量与字符向量的拼接。使用 attention 机制将原始的字符向量和词向量拼接改进为了权重求和,使用两层传统神经网络隐层来学习 attention 的权值,这样就使得模型可以动态地利用词向量和字符向量信息。实验结果表明比原始的拼接方法效果更好。
在作者的实验中,上述提到的 NN 和 CNN 结构效果基本一致,但是句子级别似然函数即加入 CRF 层在 NER 的效果上有明显提高。